Terminology
- SIMT(Single Instruction Multiple Thread) : 하나의 명령어로 여러개의 스레드를 동작시킨다.(1개의 스레드=1개의 데이타 처리) (SIMD와 같은 개념)
- GPU에서 실행되는 함수를 커널(kernel)이라고 부른다.
- 레지스터는 커널에 선언되는 변수가 저장되는 메모리다.
- 커널 호출에 의해 생성된 모든 스레드(Thread)를 그리드(Grid)라고 한다.
- 그리드는 많은 스레드 블록(Block)으로 구성된다. (max_grid = (2147483647, 65535, 65535))
- 스레드 블록은 스레드들의 묶음이다. (max_thread = 1024 threads/block)
- SP(Streaming Processor: GPU의 기본단위, cuda core)는 GPU architecture에 따라 n개의 스레드로 구성되어 있다.
- SM(Streaming Multiprocessor)은 8개의 SP로 구성되어 있다.
- SM의 32개의 스레드를 워프(Warp)라는 단위로 정의하며, 실행의 가작 장은 단위가 된다.
Reference - https://stackoverflow.com/questions/3519598/streaming-multiprocessors-blocks-and-threads-cuda - http://donghyun53.net/nvidia-gpu-%EC%95%84%ED%82%A4%ED%85%8D%EC%B2%98-%EB%B3%80%EC%B2%9C%EC%82%AC-%EC%83%81%ED%8E%B8/
| Software | Hardware |
|---|---|
| Thread | CUDA core |
| Thread Block | SM |
| Grid | Device |
Structure
아래와 같은 계층 관계를 가지고 있다.
- Grid > Block > Thread
- gridDim : 한 그리드 내 블록의 수.
- blockIdx : 몇 번째 블록인지 나타내는 인덱스.
- blockDim : 한 블록 내 스레드의 수.
- threadIdx : 몇 번째 스레드인지 나타내는 인덱스.
ex) 아래 GPU 전체 스레드 그림에서 오렌지색의 스레드가 몇 번째 스레드인지 global index를 구하는 방법
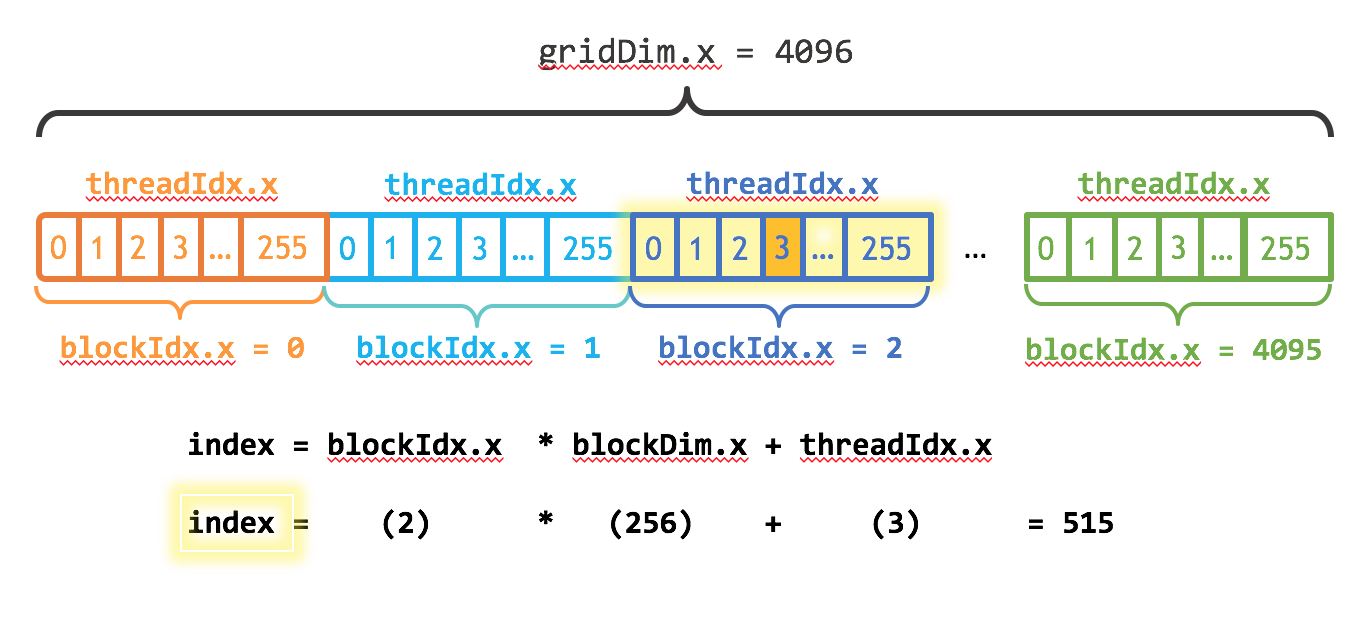 (https://devblogs.nvidia.com/even-easier-introduction-cuda/cuda_indexing/)
(https://devblogs.nvidia.com/even-easier-introduction-cuda/cuda_indexing/)
Kernel Function
| Function | Run on | Call from | Return type |
|---|---|---|---|
__global__ |
Device (GPU) | Host Device in up to Compute capability 3.5 |
void |
__device__ |
Device (GPU) | Device 그리드와 블록을 지정할 수 없다. |
|
__host__ |
Host (CPU) | Host | optional |
- 커널 함수는 반드시 void return type이어야 함.
Kernel 호출
function_name<<<nBlock,nThread>>>(argument list);
nBlock: 블록의 개수nThread: 각 블록에서 스레드의 개수
Runtime API
__host__cudaError_t cudaGetDeviceProperties(cudaDeviceProp *prop, int device)
: 지정된 디바이스의 정보를 반환
prop: 지정된 디바이스에 대한 속성device: 속성을 얻고자 하는 디바이스 번호
__host____device__cudaErro_t cudaMalloc(void **devPtr, size_t_size)
devPtr: 디바이스 메모리에 할당될 포인터size: 요청되는 byte 단위의 할당크기
__host____device__cudaErro_t cudaFree(void *devPtr)
devPtr: 해제될 메모리에 대한 디바이스 포인터
C로 작성된 파일을 Cuda로 compile할 때
nvcc -arch=sm_70 -x cu hello.c -o a
Batch file
#!/bin/sh
#SBATCH -J gpu_05
#SBATCH --time=00:05:00
#SBATCH -p dual_v100_node
#SBATCH -o result.out
##SBATCH -e result.err
#SBATCH --gres=gpu:1
srun ./a